

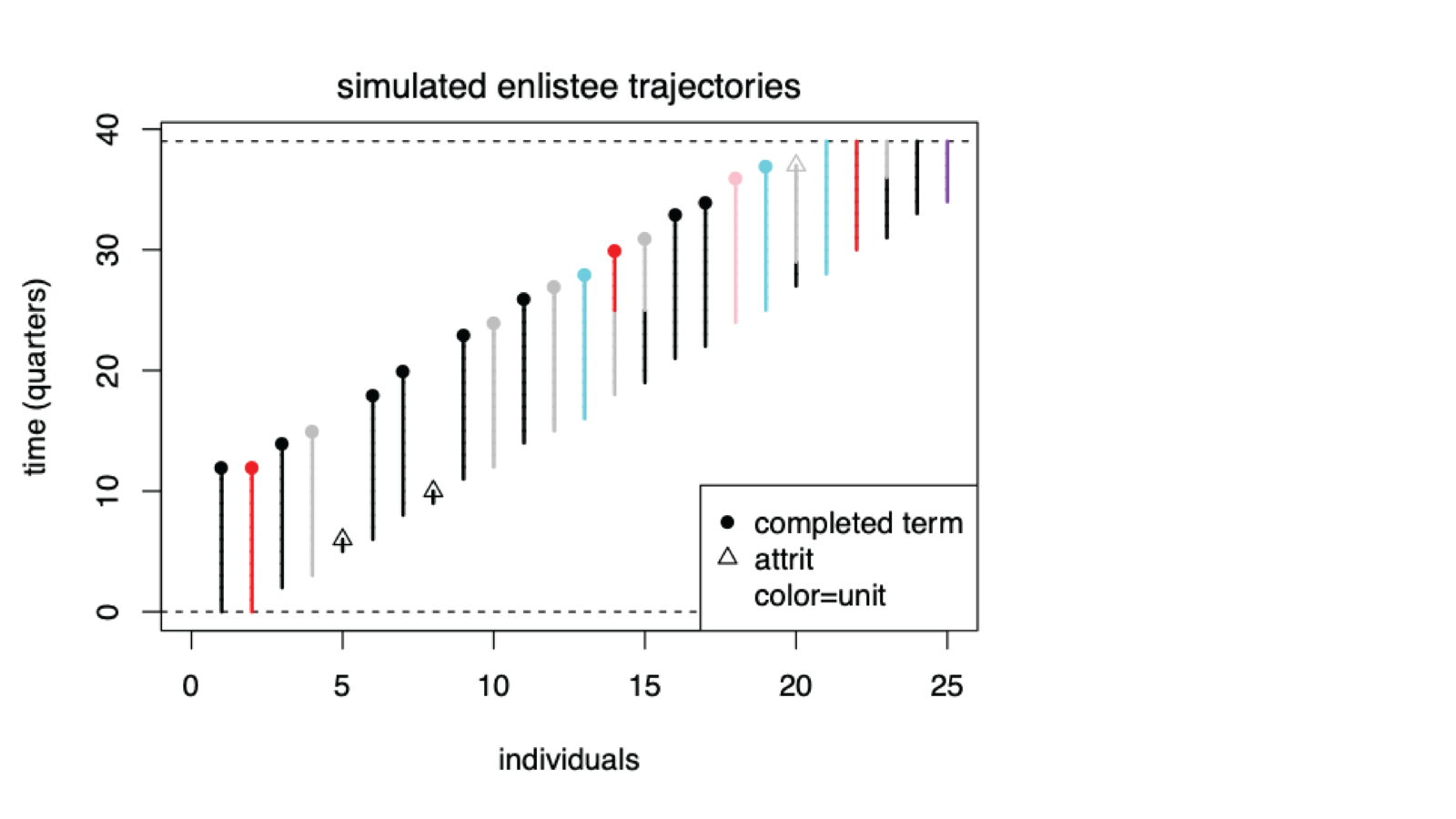
To start we simulated records from an agent-based model to create a digitaltwin of theArmy for characterizing how attritions take place. Starting with this controlled, synthetic system allows us to encode simple, probabilistic rules that affect attrition. For example, attrition probability may depend only upon the unit the Soldier belongs to and the length of time they have served. Simulated records from this model are used to refine and test the attrition model before implementing it on the full Army dataset within PDE.
Figure 1 shows an agent-based model output for over 10 years of enlistments and attritions. This simulated enlistment histories are for individual Soldiers over the course of 10 years with Soldiers.
Using this simulation approach allowed us to refine the final method, a Bayesian hierarchical discrete-time hazard model. This approach is able to handle multiple time scales (e.g. year and time of service), random individual effects (e.g. and individual’s taste for military service), and flexible, non-parametric specifications for continuous effects (e.g. age, days deployed). Efficient inference for model parameters is done via Markov chain Monte Carlo.
The full model uses DOD data from a variety of sources within the PDE including a master personnel file, an analyst file with data collected at enlistment, and a transaction file. These provide individual (de-identified) data on the enlistees and their characteristics, information prior to entering the Army such as test scores and educational attainment, and transactional information (or events) upon joining the Army, including information on promotion progression, duty location, and attrition. Other data on training, physical fitness, and disciplinary actions are linked from the Digital Training Management System (DTMS) and Interactive Personnel Elective Records Management System (IPERMS). Non-DOD estimates from the American Community Survey (ACS) and Bureau of Labor Statistics Quarterly Census of Earnings and Wages (QCEW) are also included at the county level. These variables offer a description of the community surrounding the location where a Soldier is stationed.
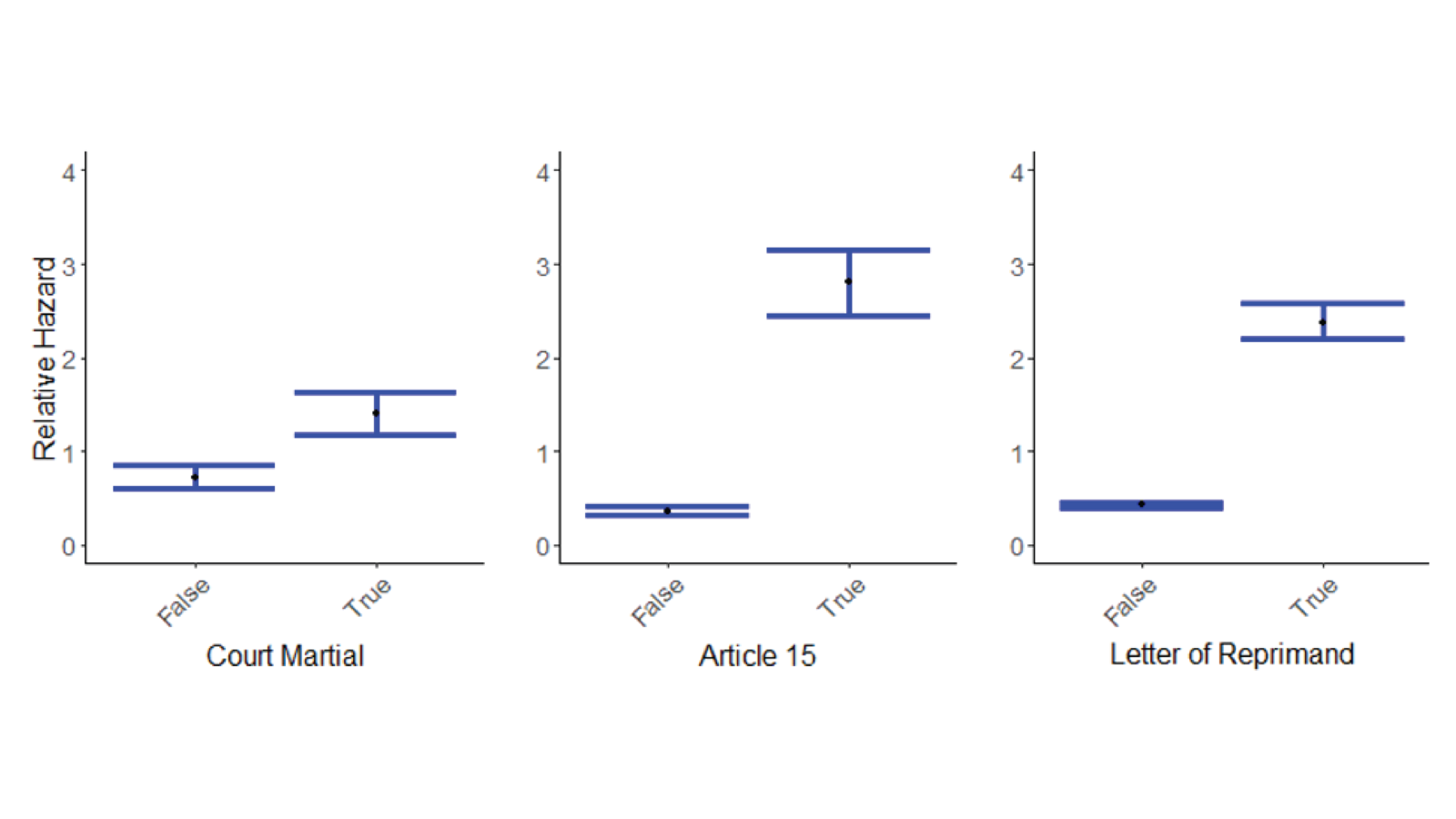
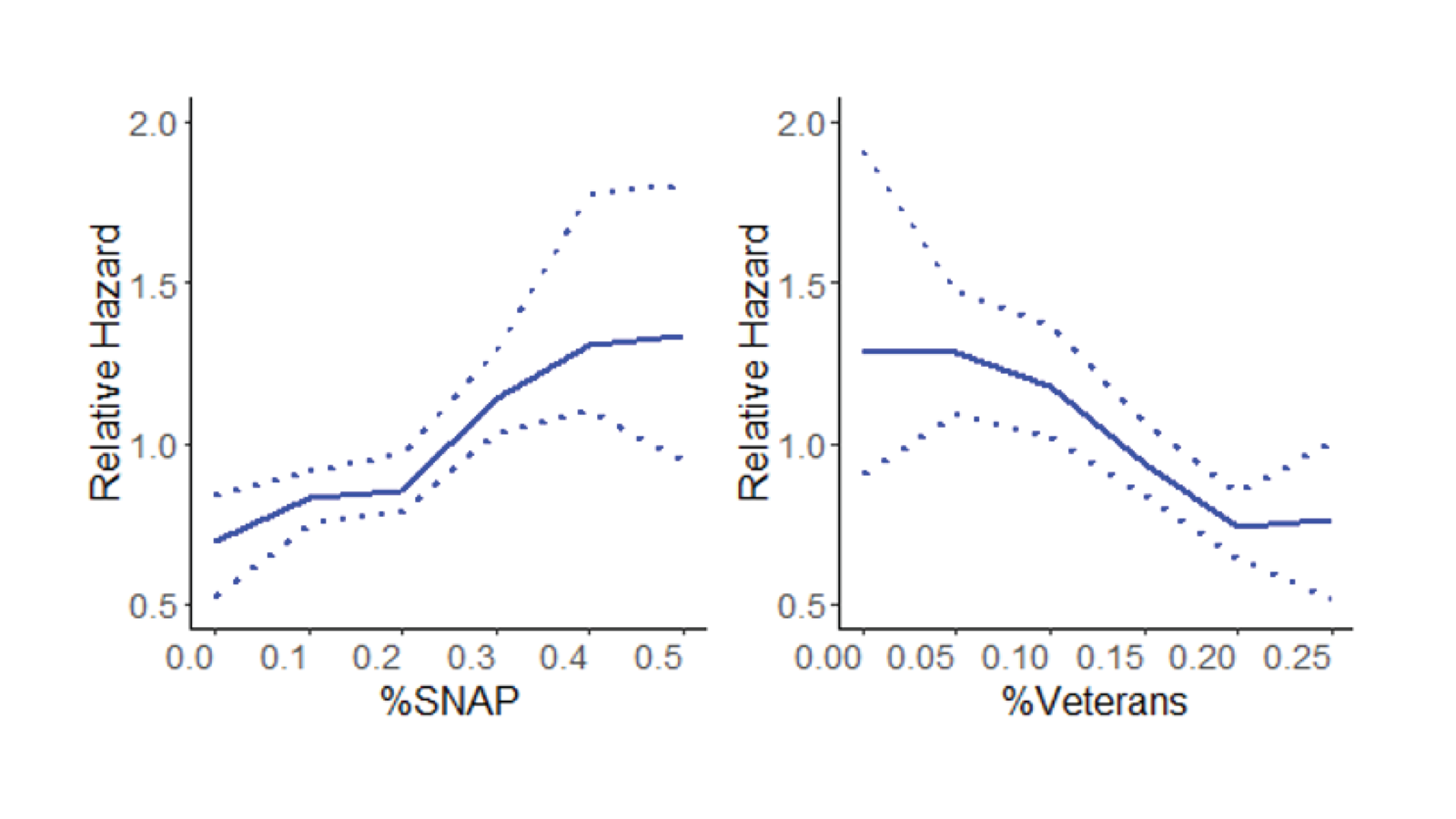
Figures 2 and 3 show some of the results from this model. In Figure 2, we see the risk of attrition is much higher for Soldiers for whom we observe disciplinary actions including courts martial, article 15 hearings, and letters of reprimand. In Figure 3, we look at the characterization of the community around the base where a Soldier is currently serving. We find that lower income communities are associated with a higher risk of attrition, while communities with a large veteran population are associated with a lower risk.
Figures

Distinguished Professor in Biocomplexity, Biocomplexity Institute
Professor of Public Health Sciences, School of Medicine
