Federal RePORTER summarizes information about scientific awards granted by the federal government, which makes it a reliable source for building a data set comprised of R&D projects. Starting with abstracts and project information for more than one million R&D grants entered into the Federal RePORTER system from 2008 to 2019, we wrangle the data to facilitate the natural language processing approach, from imputing missing information, removing duplicate abstracts, and cleaning the abstracts using standard natural language processing steps. These steps include lemmatization, stop word removal, and applying bi-and tri-grams definitions.
Detecting Emerging R&D Topics
Topic modeling is a machine learning method used to identify underlying themes (i.e., topics) within a corpus of documents, where each document is composed of multiple topics. Based on testing different topic modeling algorithms, we selected non-negative matrix factorization (NMF) as the most accurate for our corpus of data. The NMF approach assigns a weight for each word in each document and penalizes words that appear in many documents in the corpus.
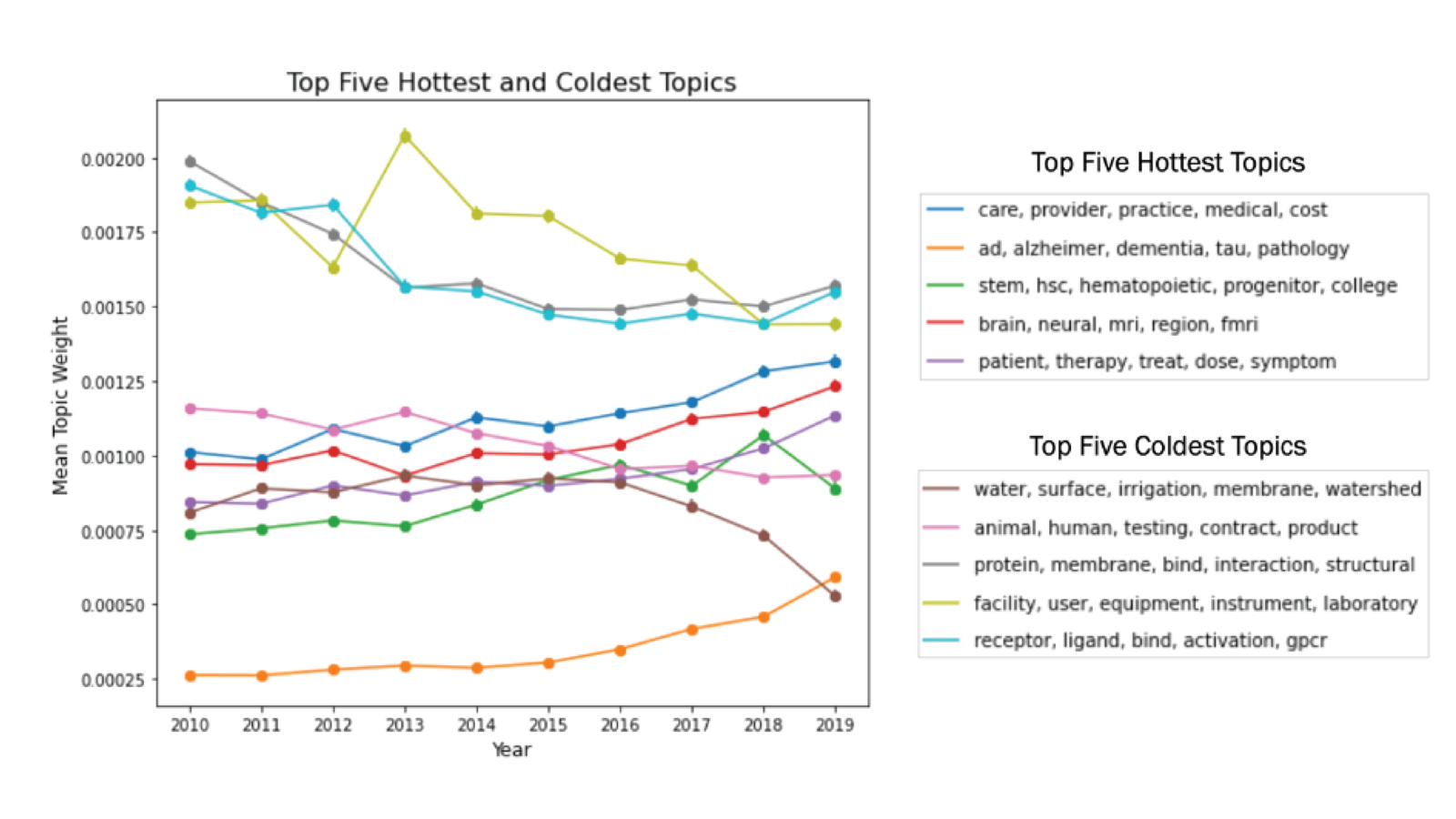
The topics that emerged from our analysis represent content areas within this corpus of federally funded R&D projects. The top five hot topics (increasing popularity over time) and cold topics decreasing popularity over time) are presented in Figure 1. These hot and cold topics are defined by larger positive and negative slopes of their respective regression lines. The coldest topics can still be popular, but just trending downward in prevalence.
Pandemics Case Study
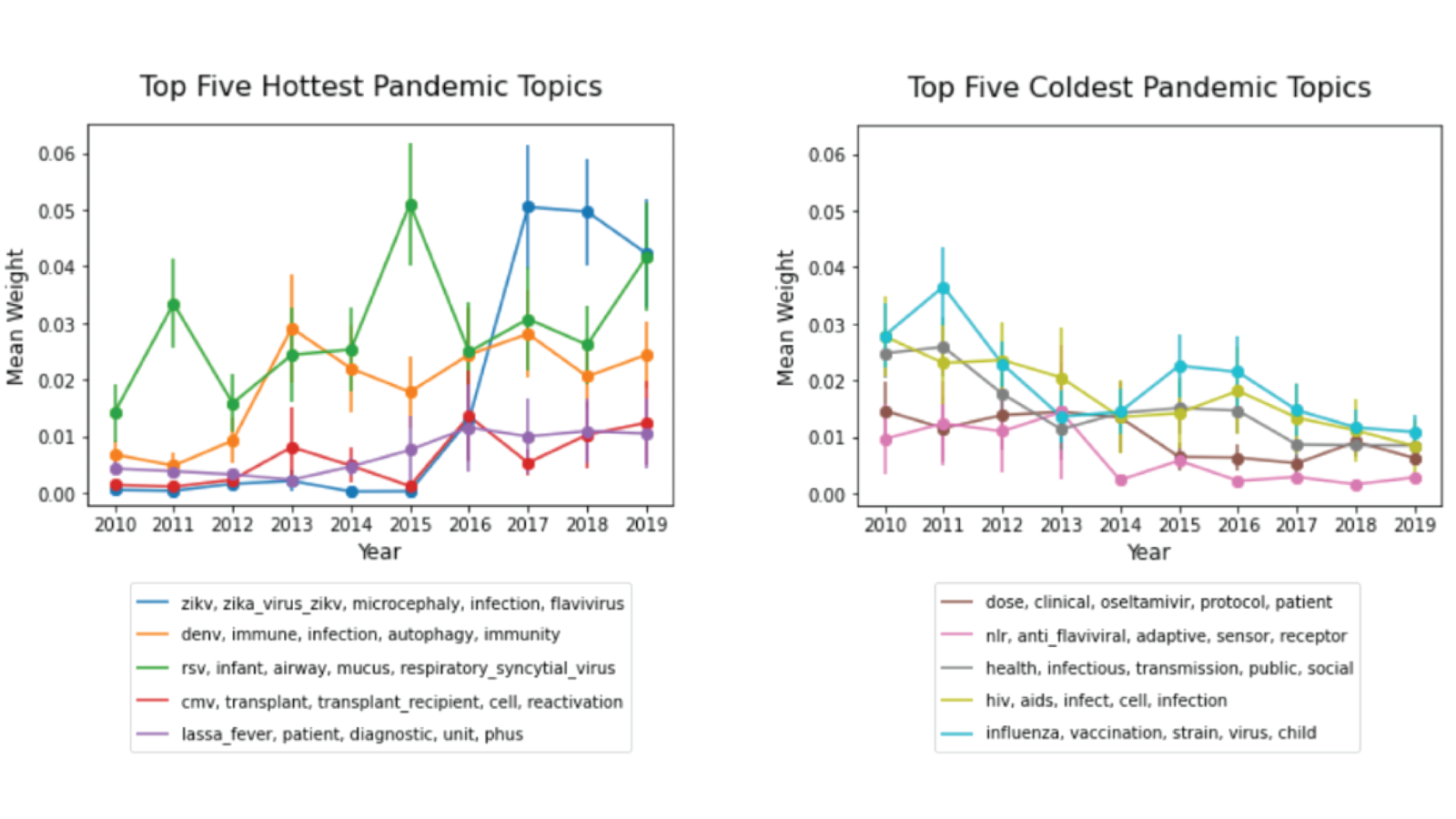
As a new coronavirus creates a crisis unprecedented in our lifetimes, there is a surging interest in pandemics research. This case study presents R&D trends about pandemics and closely-related research. The five hottest and coldest pandemic R&D topics are presented in Figure 2. The results show a sharp increase in Zika virus research after the outbreak in 2015-2016 (see hottest topics chart) and an increase in research in influenza in 2010 and 2011 after the swine flu pandemic in 2009-2010 (see coldest topics chart).
Figures